 SQL Servers are great general purpose tools. They’re popular because they perform OK at just about everything you could want to do with data.
SQL Servers are great general purpose tools. They’re popular because they perform OK at just about everything you could want to do with data.
If you want to do something specialised however then there are almost always better techniques. Recently I needed to get medium sized sets of records identified by key, dispersed at random over an essentially read-only data set.
MS SQL Server is OK at this, but there are a bunch of products out there that are far better at this task. At a basic level though it’s not actually a difficult thing to do. It’s just a key-value lookup after all. So I wondered if in a few lines of code I could out-perform SQL Server for this one specific task.
Essentially all I did was to dig up the ISAM file. All that really means is that the main data is serialized to a file. All we store in memory is the ID (that we search for) and it’s location within the file. I then implemented a balanced b-tree to store the relationship between the ID and the file location. You could use a Dictionary<Key,Value> for the latter, it would be a bit slower but it would work. You really don’t need to write a lot of code to implement this.
So in ISAM vs. SQL Server I have on my side;
- A simple, really fast search algorithm
- No need for IPC.
- No need to parse the query
- No need to marshal writes, manage locks or indeed worry about concurrency at all
SQL Server has on its side;
- Huge expertise and experience in optimising queries and indexes
- Super-advanced caching meaning it doesn’t face the same I/O problems
Before the days of the SSD I’d say attempting this was pretty insane. The main problem with the performance of a mechanical disk is the head seek time. You can get data to and from the disk pretty fast provided that the head is in the right place. Moving the head however is massively slow in comparison. So if you have a large file and you need to move the head several times then you’re going to lose a lot of time against a system that has an effective cache strategy.
Half the battle with an ISAM file was to get the records that were going to be read together physically close to each other in the file so that the heads didn’t move much and the likelihood of a disk cache hit was much higher. It’s this kind of management where complex RDBMSs will always have the upper hand.
However SSDs have no head seek time. It doesn’t matter if you need to read from many locations. This rather levels the playing field.
Interestingly I did notice a small speed improvement when I implemented a parallel ID lookup and sorted the results so the FileStream read in sequence from first in the file to last. I’m guessing that this is down to the read-ahead cache (which is still faster than the real storage media).
So did I make it? Can a simple technique from yesteryear embarrass today’s latest and greatest? I wrote a little console app to test…
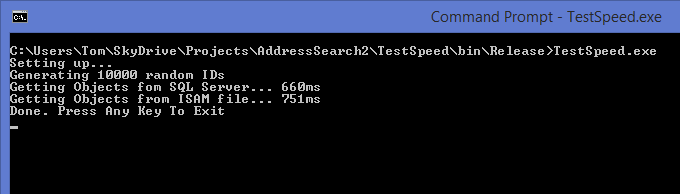
Not bad, SQL Server is 15% faster which is a pretty reasonable result. After all I couldn’t really expect to beat SQL Server with just a few lines of .NET, right?
Yeah, I’m not beaten that easily. So I cracked open Visual Studio’s Performance Explorer and found an obvious bottleneck. It turns out that .NET’s BinaryFormatter is dog slow. I tossed it out and replaced it with ProtoBuf-Net.
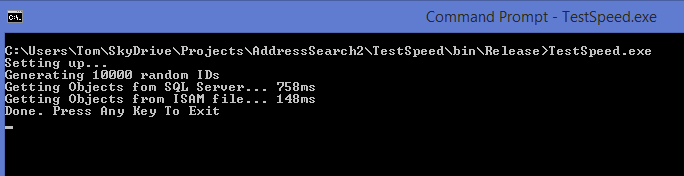
Oh yes, that’s much better. This is pretty consistent too. I was using SQL Server localdb which actually seems to be a reasonable analogue. It might be interesting to see it against an enterprise level installation. I suspect that the additional network latency will compensate for the additional performance at it will perform about the same.
So in other words, yes if you have a very specific task and you know what you’re doing then you can outperform the big boys.
So I suppose I should publish the source – but right now it’s horrible. Its only purpose was to prove that I could do it. I’m intending to tidy it up and post it in a different article.