One thing about C# style that I get asked quite a lot is why I tend to write if statements like this…
if (null != args)
{
It’s not how most people think. It seems far more logical written this way round…
if (args != null)
{
It’s actually a hang-on from my days as a plain old C developer, most of the time it’s not relevant to C# but there’s one particular instance where it is.
bool someBoolean = false;
bool someOtherBoolean = true;
if(someBoolean = someOtherBoolean)
{
Console.WriteLine("The if condition evaluated to true!");
}
Console.WriteLine(String.Format("someBoolean is [{0}], someOtherBoolean is [{1}]", someBoolean, someOtherBoolean));
So when we run this, we might not get the result we expect.
This is because in C# assignment operations have a result. Instead of comparing the two items in the if statement (==) we assigned the value in someOtherBoolean to someBoolean (=). Basically we just used = where we should have used ==, it’s an easy mistake to make and in this instance it compiles and runs, it just doesn’t do what we want, at all…
I actually wrote about this in an article some time ago, but back then I was talking about doing it deliberately, and as part of a work of extreme evil.
OK, so that’s a convoluted example and in reality you’re unlikely to cause yourself serious problems in C# because C# is very strict about the result of whatever’s in an if statement being Boolean. So if you did accidentally write this, it wouldn’t compile.
if(someObject = null)
{
someObject = new someType();
}
This is because the result of assigning null to someObject is null, which is not a Boolean.
However in C the equivalent will compile and will run. In C anything that evaluates to zero is treated as false and anything that evaluates to non-zero is treated as true.
This will crash every time, because we’re actually assigning NULL to the value someStruct. The result of that assignment is zero, which evaluates to false, so execution skips the contents of the if statement and goes directly to where the structure is accessed – the structure that we’ve just assigned to NULL.
This is my mobile phone, or cellphone if you will. It’s a HTC Wildfire S running cyanogenmod 9. Sure it was never an expensive phone but I didn’t get it because it was cheap, I got it because it was small.
I am notoriously hard on kit. Something like a mobile phone just gets shoved in my pocket and ends up doing whatever I do. Scaling roofs to find mobile phone signal is perfectly normal in my world, as is climbing into the loft, crawling into tight gaps and running out in a howling gale to rope the remains of the fence to something a little more stable.
Amongst my friends, many of whom have the same attitude to life as me, there is a catalog of broken phone screens. My little Wildfire S has lasted a few years now without any serious damage.
It is however getting a little long in the tooth. It never had even remotely enough memory to start with and fiddling it to make it think that a portion of the SD Card is actually internal memory isn’t the most reliable. It’s also suffering a bit with a lot of modern apps which are a getting a bit slow.
So I’m in the market for a replacement – I figured this should be easy as there are a lot of new “mini” phones on the market. Only they’re not, the new “mini” phones are only mini compared to their tablet-size counterparts.
The look of horrible confusion on the face of a mobile phone stores salesperson is one I’ve got well used to, “sorry, I’ll just repeat that. I’m looking for a small, tough smartphone. Not a 6 inch mini-tablet that will break as soon as I attempt to climb a ladder with it in my pocket.”
I’m never far from a PC, a laptop or a tablet. I don’t need a mobile mini-tablet, what I need is a smart-phone, something that fits in my pocket and allows me to check social media and run a few tracking and navigation apps and maybe listen to Buddy Guy.
Reading Time: < 1minuteActual Bread! From My Oven!
It’s not a big thing, especially considering all the culinary adventures I’ve had, but up until 7pm this evening at no point in my life had I ever attempted to bake bread. Those two mini-loaves on the right are my first ever attempt and not only do they look like bread they actually taste like bread too!
As a child I was fascinated by how my mother would mix the dough and kneed it. Then the magic started – the dough would rise. Then she’d bake it and we’d have bread. My mother made bread, wonderful smelling soft bread. Most people had to buy bread, but my mother could make it. To my child’s brain that was very impressive.
This probably explains why I’ve been entirely happy to undertake some ludicrously complex and technical culinary challenges but to date not bread baking. I was scared. I was scared that I might not be able to do it and that if it didn’t work it would ruin the memory of that smell. It would ruin part of my childhood.
But it did work, and actually to me it’s quite a big thing.
Round trips to SQL Server kill performance. It takes time to set up the command, get it to the SQL Server, then to parse it, search for and format the results then return them to the application. If you need lots of little pieces of information this can get extremely frustrating, especially when you get a call from your DBA about the “horrible” app that you’re developing.
Sometimes you can bring back a super-set of the data you need in one query rather than several smaller queries and you may find that filtering the data down to what you need in code is faster than hitting SQL Server with lots of small queries. It is subjective, of course. There’s always a level in database programming where the theory is fine but you don’t really know until you try it.
I found myself thinking that there must be a better way though. There are two scenarios I want to cover – let’s start with the simpler one.
My Selection Criteria is Complex – e.g. It Contains a List
Wanting to pass a list as an input parameter to SQL Server is a common problem, and one that I’m pleased to say Microsoft addressed in SQL Server 2005 with table valued parameters. Except that they didn’t implement it in Linq-to-Sql or Entity Framework which proves a bit of a headache.
Table valued parameters also need to be in the schema and that’s not always under the control of the app developer. So what do you do if you’re stuck in hard place where you can’t do it the right way?
Let’s say Northwind – Microsoft’s now ancient example company – was integrating to another system. That other system might want details of several customers. Helpfully they can provide us list of the IDs they require. This is easy if you’re typing the SQL in directly…
SELECT * FROM dbo.Customers WHERE CustomerID IN ('BERGS','GODOS','FURIB','GREAL')
You can of course build up the query text in code to be just like the above but you’d better pray that “Little Bobby Tables” never becomes a customer.
Naturally you can use a stored procedure to parse a CSV type string but whilst that’s not so open to a Sql injection attack it’s still pretty fragile.
A more robust way is to use XML. Here’s some C# with everything hardcoded so, as long as you have a Northwind somewhere, this should work via the magic of cut-and-paste (and editing the connection string).
private void GetCustomersByID(List<string> list)
{
//make an XML document listing the customer IDs
XElement doc = new XElement("customers");
list.ForEach(customer =>
doc.Add(new XElement("customer", new XAttribute("CustomerID", customer))));
//Connect to the SQL Server
using (SqlConnection connection = new SqlConnection(@"Server=(localdb)\v11.0;Integrated Security=true;Initial Catalog=Northwind"))
{
connection.Open();
using (SqlCommand getCustomers = connection.CreateCommand())
{
getCustomers.CommandType = System.Data.CommandType.Text;
//Command text uses the XML document to join to the target table as a way of selecting rows
//(there are other, probably better ways)
getCustomers.CommandText =
"DECLARE @hdoc INT " +
"EXEC sp_xml_preparedocument @hdoc OUTPUT, @xml " +
"SELECT [dbo].[Customers].[CustomerID], [CompanyName], [ContactName], [ContactTitle], [Address], [City], " +
"[Region], [PostalCode], [Country], [Phone], [Fax] FROM [dbo].[Customers]" +
"INNER JOIN OPENXML(@hdoc,'/customers/customer',1) WITH (CustomerID nchar(5)) req " +
"ON req.CustomerID = dbo.Customers.CustomerID " +
"exec sp_xml_removedocument @hdoc";
getCustomers.Parameters.AddWithValue("@xml", doc.ToString());
//bring the results back and display them
using (SqlDataReader resultsReader = getCustomers.ExecuteReader())
{
while (resultsReader.Read())
{
object[] values = new object[resultsReader.FieldCount];
resultsReader.GetValues(values);
Console.WriteLine(String.Join(", ", values.Select(x => x.ToString())));
}
}
}
}
So we make an XML document in C# – there are any number of ways of doing this, I chose LINQ’s XElement – and passed it to the SQL Command as a parameter. We then use OPENXML to open it as a rowset and inner join it to the target table, allowing us to bring back only the rows we want.
Of course there is an overhead in constructing the XML and parsing it in SQL Server and we must be aware of that, but this little trick does allow one to neatly work around some quite common problems.
Of course this example is a little trivial. It’ really only to demonstrate a technique. Where XML particularly wins – even over Table Valued Parameters – is that XML does not need to be a list of the same type. You could even specify groups of parameters or a complex structure enabling the SQL Server to make some informed choices about the data to return without having to issue multiple queries and incur unnecessary round-trip overhead.
I Want to Return Complex Information Made From Many Fragments of Data
This usually manifests itself when you need data from several tables where there isn’t a one-to-one relationship.
If the relationship is simple sometimes it’s quickest to use a join and just throw away the duplicated sections of the row. e.g. you might want a the customer details and their 50 most recent orders – you can accomplish this with a join but you’ll get a copy of the customer’s details with every order details so that’ll be 49 copies of the customer’s details that you don’t need. It may be faster than using 2 separate queries.
You can also return multiple result sets from a query or stored procedure. Scott Gu covers that quite adequately in LINQ-to-SQL Part 6. In the above example you could return two result sets, one containing the customers and the other containing the orders. You’d then have to link them in code, but provided there aren’t too many rows this can be a quick option.
If it’s details of just one customer that you need you could return one result set (the orders) and use OUT parameters in the query – that’s another option.
I mention these options first because XML may not be the right way to go, I’m really just presenting it as an option that you could take. To that end let’s look again at the Northwind database – perhaps we want to bring back a lot of information about a customer, maybe the orders they’ve placed and what was in those orders. This is a hierarchical data set, of course we could do this with multiple result sets but we’d have to join them up on the client side and that could get messy. Instead we can use SQL Server’s ability to output XML. Of course batting XML around the place instead of nice binary types is going to incur a significant overhead and that should be taken into account, but there is potential here.
SELECT [CustomerID]
,[CompanyName]
,[ContactName]
,[ContactTitle]
,[Address]
,[City]
,[Region]
,[PostalCode]
,[Country]
,[Phone]
,[Fax]
,(SELECT [OrderID]
,[CustomerID]
,[EmployeeID]
,[OrderDate]
,[RequiredDate]
,[ShippedDate]
,[ShipVia]
,[Freight]
,[ShipName]
,[ShipAddress]
,[ShipCity]
,[ShipRegion]
,[ShipPostalCode]
,[ShipCountry]
,(SELECT [OrderID]
,d.[ProductID]
,[Quantity]
,[Discount]
,[ProductName]
,[SupplierID]
,[CategoryID]
,[QuantityPerUnit]
,d.[UnitPrice] [OrderUnitPrice]
,p.[UnitPrice] [ProductUnitPrice]
,[UnitsInStock]
,[UnitsOnOrder]
,[ReorderLevel]
,[Discontinued]
FROM [dbo].[Products] p INNER JOIN [dbo].[Order Details] d ON p.ProductID=d.ProductID
WHERE d.OrderID=o.OrderId FOR XML PATH('OrderDetail'),ROOT('OrderDetails'),TYPE)
FROM [dbo].[Orders] o WHERE o.CustomerID=c.CustomerID FOR XML PATH('Order'),ROOT('Orders'),TYPE)
FROM [dbo].[Customers] c FOR XML PATH('Customer'),ROOT('Customers')
GO
The cunning bit here is using SQL Server’s subquery ability to produce a hierarchical XML dataset.
The root node is “Customers” containing multiple instances of “Customer”. Each Customer contains an “OrderDetails” element which is a list containing multiple instances of “OrderDetail”. This in turn has a “Products” element which is a list of “Product” items.
I won’t go into SQL Server’s ability to produce XML in any great deal suffice to say that it’s come a long way since 2005 and it’s now really quite powerful. I also accept that there may be better ways of achieving the above.
What I do need to mention is how to get this back to a C# app – don’t be tempted to use ExecuteScalar() – it will truncate long xml.
The following uses XmlReader which is in turn used with an XmlDocument. This is the asynchronous model which allows a little more responsiveness in the GUI, but does mean a lot of Dispatcher.Invoke().
What I did with the above was to bring it back straight into a WPF GUI and use WPF’s ability to databind directly to XML. Then curiosity got the better of me. I copied the app and produced a version that was almost identical, but used Linq-to-Sql and bound directly to the object model.
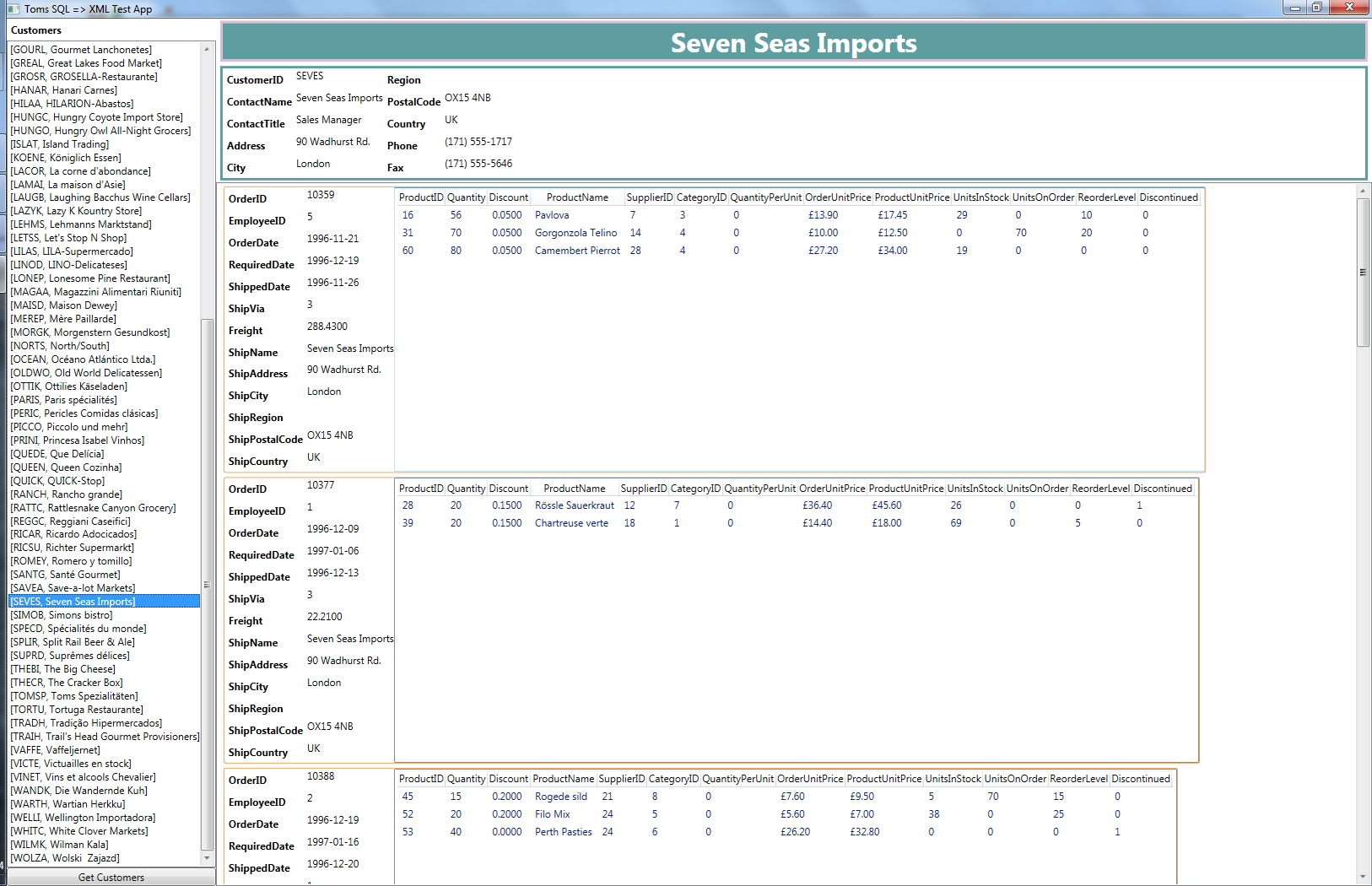
SQL to XML Example App
In use there doesn’t appear to be too much difference between them. I think the XML version is slightly faster but I accept that I may be biased. We’re dealing with a very small data set on a local server however so it’s not really surprising that there’s no immediately obvious difference. To get some results we have to look at SQL Server Profiler.
So I made sure that I did the same repeatable action – I first loaded a list of all the customers and then I selected just one customer, Seven Seas, for display. The differences are remarkable.
Profile of Data Retrieval Using XML
SQL Server Profiler of XML Retrieval
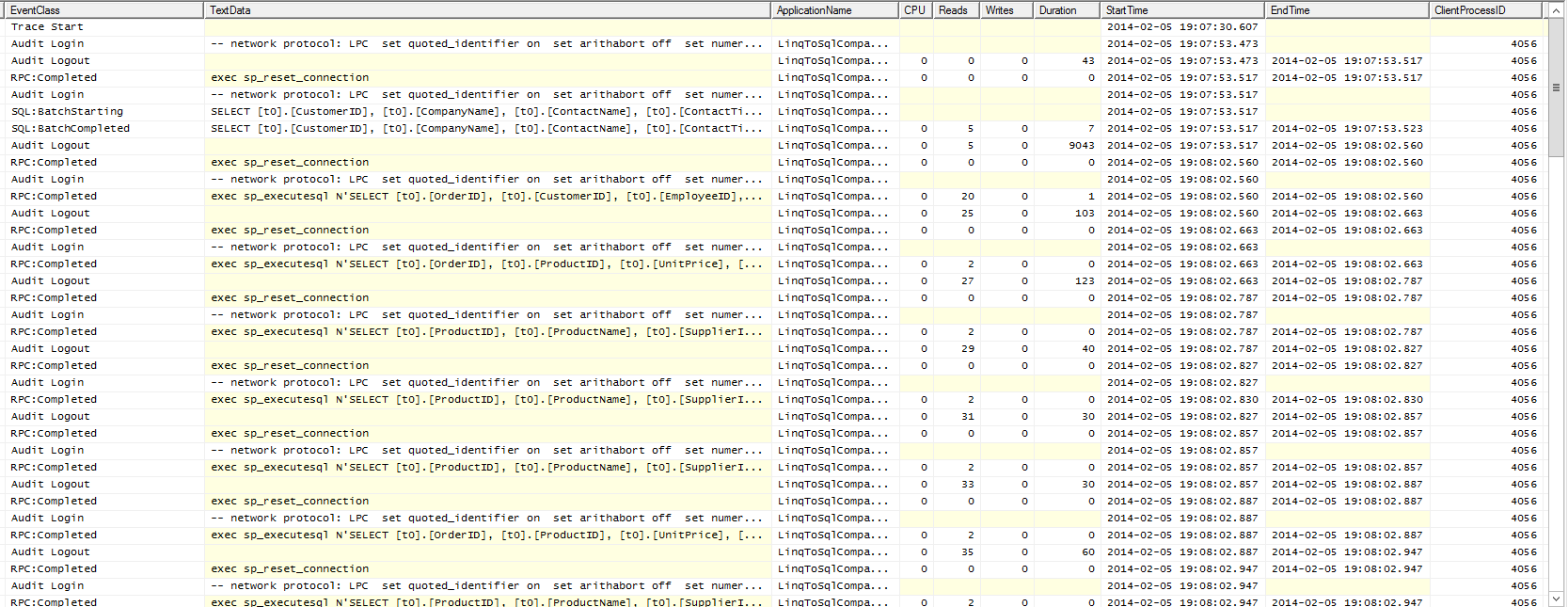
Profile of Data Retrieval Using LINQ
SQL Profile of LINQ Retrieval
What we can see here is Linq-To-Sql issuing a rash of tiny queries to pick up lots of individual pieces of information.
Conclusion
The real conclusion is that I probably didn’t pick a great example. It’s clear however that the approach of Linq-to-Sql and my XML based method are polar opposites, the former hitting Sql Server with a rash of small queries, the latter with fewer, much larger ones. Even on local servers round trips cost and I suspect that as the number of users increased and the size of the data increased the performance of the Linq-to-Sql version would start dipping much faster than that of the XML based version.
In the production environment I tend to use multiple result sets because it generally works out cheap to rejoin them on the client side. It’s nice to know however that XML is sitting there in my back pocket, giving me an alternative.