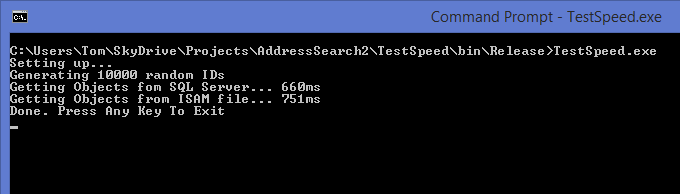
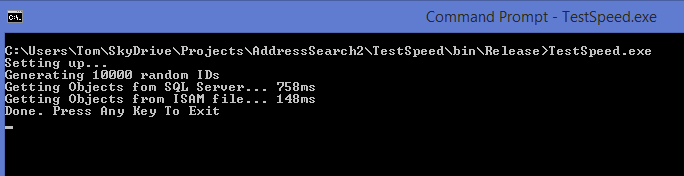
Reading Time: 7 minutes “WE MUST HAVE THIS FIXED ASAP!” yells the customer’s head of ICT. The application stopped working some time last week and your support department haven’t managed to fix it yet.
“WE MUST HAVE THIS FIXED ASAP!” yells the customer’s head of ICT. The application stopped working some time last week and your support department haven’t managed to fix it yet.
“OK, OK,” you say, knowing that you will come to regret these words, “I’ll VPN in first thing tomorrow and sort it out. Will you send me the connection details.”
“I’LL SEND THE CONNECTION DETAILS IMMEDIATELY I GET OFF THE PHONE AND YOU CAN CALL WHEN YOU WANT TO CONNECT”, replies their head of ICT, because heads of ICT ALWAYS SPEAK IN CAPITALS.
08:00 the next day, no email. Send an email to the customer’s head of ICT reminding them that you need the VPN details.
No response. OK, fair enough, a lot of people don’t get in ’til 9am.
09:30 still no response. Email a bunch of other guys at the customer’s site asking if anyone knows the VPN details and is actually authorized to give them to you. Get a response saying that only the head of ICT is and he’s in a meeting ’til 10:30.
Wait ’til 10:45, no response. Try to find a phone number for the customer’s head of ICT. Apparently he doesn’t have a phone. Email him again. 11:15 get a rather terse email containing the connection details and the username and password in plain text.
Try them, they don’t work. No phone number in provided in the email. Try to find a phone number of anyone in the organisation who might actually be able to help. Find an old mobile number that now belongs to a photocopier salesperson who can’t really talk because she’s on the motorway, but she could do you a really good deal on a pre-owned Canon IRC3380i if you call back later.
Google the customer to try to find a switchboard number. End up in a multilevel call menu system where the only human option is to speak to a “customer relationship manger” about your account. Try that on the offchance. He thinks you’re from their ICT department and has no idea what you’re talking about.
11:30 Remember that you may have stored some old details for the customer’s other site, log in to the password vault. Find some that are 4 years old. Try them anyway, are genuinely surprised when they work. Make a mental note to inform the customer that they seriously need to do a security review.
Connect to the server the head of ICT said was the right one. Credentials don’t work. Neither do the stored ones. Email the head of ICT and everyone else you can think of who might possibly know how to log on to the server. Get no response.
12:00 Remember somewhere in the back of your mind that you once configured SQL Server authentication for one of their systems and there’s just a chance that they re-used the username and password from a domain account.
Log into the secure store and search the archived configs. Find a likely candidate and try the connectionstring details.
12:15 Scratch the head of ICT’s name into the side of a giant security rocket and direct it at his arse when said credentials actually work.
Spend half an hour setting up the diagnostics. Scratch head as to why nothing’s happening.
13:00 deduce that it’s the wrong server. Email the head of ICT and go for lunch.
13:30 return to an email from the head of ICT who is now working from home and doesn’t have the details to hand but has emailed an unnamed member of his team asking them to send them on.
Log back in to the wrong server. Expand the network section and have a look at the machines listed there to see if any of them look likely. No, but it does spawn an idea. Look back at the connectionstring from earlier and note that the Data Source is a name that ends -SQL try connecting to the same name with -GW on the end.
No dice. Try various combinations.
13:47 Eventually try -SVR4 and it works. Try the credentials from the connectionstring, they don’t work. Try the original details the head of ICT sent in the email, they work, but Remote Desktop is not enabled for that user. Try VNC with the same credentials, just in case. Nope.
Email the one person who responded earlier, carefully include a request for a phone number.
14:15 Get a response that contains no phone number but which politely explains that although the person can’t make the change Jack will when he gets back from lunch at 14:30.
14:45 Try logging in again. Still not enabled. Take 6 guesses at what Jack’s email address might be and email them all.
14:53 Field a call from the Customer’s Operations Director who is extremely angry that the system is still not working and your bungling incompetence at not being able to sort out your own software. Explain that there are some technical problems with the VPN connection that you’re trying to resolve right now. Try to persuade him that half hourly updates are not going to help anything and in fact are only going to slow things down.
15:07 Get an email from Jack confirming that he’s enabled the user for Remote Desktop. Log in to the server. Go to the application directory under Program Files and check the version numbers. Not only are they wrong they’re actually a mixture of the past 3 releases. Take a backup and install the latest versions.
Try to start the service. No dice. Scratch head. Just double-check the service executable location. Find it’s actually in “C:\Temp\Barry’s Memory Stick\From Old Server”. Start to get rather concerned that the customer’s assurances that “No we haven’t changed anything” omitted one small detail – the fact that they installed the app on a totally different server.
Look in the event log at the error that’s actually being reported – it transpires that none of the well documented pre-requisites for installing your application have actually been installed. Attempt to download them only to find that the server can’t connect to the Internet.
Start downloading them locally instead and pushing them one-by-one to the remote server.
15:35 Field another call from the Customer’s Operations Director who is extremely angry that he hasn’t got the half-hourly update that you talked him out of and that the system still isn’t working. Explain to him that escalating this won’t help because you are the most senior person that could possibly work on this and it’s your number 1 priority, the only thing it will do is create more admin load for everyone including him. Pretend to try transferring the call to your own CTO’s phone, pretend she’s not answering.
15:55 Ring your own CTO to let her know the situation and to expect an angry call imminently.
16:03 Final prerequisite installed; the service now starts, but it can’t connect to the database. Check the connection string. Note that it’s trying to connect to your own testing server – this is clearly the default config that someone has carelessly copied over the site config. Look at the other copy of the software and find a comment in the config that say’s it’s from Barry’s test system. There appear to be no backups of any version of the config.
Search the entire filesystem for anything that might be a past version of a valid config whilst taking a few random guesses at what the SQL Server might be called.
Email Jack asking if he knows what the configuration should be or at least where the old server is.
16:19 Answer a call from your own CTO who would just like to confirm that you really are doing everything you can. She tells you not to worry about “that email”.
16:21 Receive email from your CTO to their Operations Director into which you’re Bcc’d assuring him that his problem is “our top priority” and that disciplinary proceedings have been started against the employee he spoke to earlier for his “bad attitude” and that the situation is now being dealt with by “someone more senior”.
16:27 Get a call from a random junior techie at the customer’s site who has no idea what you’re talking about but has been told to sort it out because the Operations Director is very angry and wants something done. Note the phone number he’s called from. He promises to find the information you need, ensure you get his name.
16:47 No emails or phone calls, so call the number back. The person answering the phone is not the person you spoke to earlier and doesn’t know who he is, but thinks he may be “that new guy from ICT who was here earlier”. Try to get anyone’s actual phone number out of the person you’re speaking to who says he’d gladly give them out if he actually knew any of them. He transfers you to the Helpdesk, however. The guy you spoke to isn’t in the office and it’s a Thursday so Jack has gone to pick his kids up, but Barry’s about if you wanted to talk to him.
16:52 Barry sheepishly explains that it is actually the same server but that it’s got an entirely new RAID array because nobody noticed when the first disk in the previous array died, but they noticed really rather a lot when the second one did and they were hoping that they could get it fixed before anyone – especially the head of ICT – noticed. They did find a backup, but after the last security scare the Operations Director hired an external security consultant to come in and do an audit and he said that this server should be firewalled from the main network and nobody realised that this would mean that the backups stopped working and nobody noticed that either. So the backup was from just after the OS was installed and they tried to work out how the app should be configured.
Barry is fairly sure which server the database is on, but he doesn’t know which actual database because they’re all looked after by Dave who’s the DBA and he’s on long term sick leave with a major case of stress.
16:57 Talk Barry through SQL Server Management studio and find a database that looks like a good candidate and has recent entries.
16:59 Log on to the remote server and enter the connection string into the config. Start the Services snap-in and try to click the start button. No reaction. A few seconds later Remote Desktop says the connection is lost and it’s trying to reconnect. Realise that it’s exactly 17:00 and vaguely remember something about “office hours only” in the support agreement. Check the VPN, it’s down and wont reconnect.
17:03 Email your CTO with a progress update, casually scan Jobserve.
17:10 attempt to shut down laptop to find 12 Windows Updates waiting.
17:13 ignore the incoming call from their Operations Director, leave the laptop where it is and go to the pub.
At The End of the Day
Fortunately this wasn’t a real day, rather it’s an amalgamation of things that have genuinely happened to me either trying to work on a remote site or in some cases when I’ve actually been there.
My favourite example of a customer having “not changed anything” is in here but it’s somewhat watered down from the reality. They’d had a security audit and much like the story had added a firewall between two parts of their network. They’d also deleted a bunch of users from the database where they didn’t know what those users were for.
What they’d done was to revoke the server’s access to its database and put in place a firewall that not only prevented the clients from accessing the server but stopped the server accessing the external web service that it needed.
Apparently they definitely hadn’t changed anything and the application suddenly stopped working so therefore it couldn’t have been their fault.