The Awks They Turn North-Eastward. They're Taking the Vulcans to Alderaan!
Tom Fosdick
Tom Fosdick is a software architect whose experience ranges from low level coding through to product management, delivery and customer relationships.
For nearly 20 years Tom has specialised in providing advanced technology to front line Emergency Services both in the UK and internationally.
When it comes to hardware, technical staff can badger a business senseless. Every member of technical staff claims that they could do their job so much better if they just had this upgrade or that gizmo. Without spending hours reading all the latest hardware blogs, determining what would actually be useful investment in their productivity is next to impossible.
SSD drives are a no-brainer though. The biggest bottleneck in PCs today is the hard disk, clunky, mechanical things that lose an awful lot of time whilst the heads are whizzing back and forth across the platters.
At the time of writing a 64Gb SSD Drive is about £100. I bought one more out of curiosity than anything else and slung it in my ancient 3.0GHz P4.
This video shows it loading Windows XP, logging in, then starting Word and Chrome at the same time.
I then type some rubbish in Word, navigate to Facebook and shut the PC down. The difference an SSD Drive makes is mind-bending. I’m not saying that you should replace existing hard disks with SSD drives, just slap one in with the operating system and apps on and use the old (likely much larger capacity) drive for data. That’s good business sense.
When I moved this article from its original site in about 2007, I didn’t copy all of the images — they stayed on the original host and were eventually deleted. Update June 2026: they’ve been recovered from an old archive and are now restored.
Introduction
In December 2005 it all went horribly wrong and I feared a huge repair bill when my boiler went weird. Could I save a small fortune and fix it myself? Yes, replacing the Pressure Release Valve turned out to be pretty easy.
DISCLAIMER
I’m not a gas fitter or plumber. I don’t know very much about boilers myself, but I am generally good with mechanical things. Some of this advice could be very, very bad. All I know is that it worked for me. I accept no responsibility for any consequences of anyone following any advice on this page!
The Pressure Release Valve
The Problem
If you’re just interested in how to replace the valve, skip forward to “Opening up the Boiler”.
We had a sealed radiator system that always dropped pressure. I needed to top it up about once a month, but in December 2005 it was getting serious. Over the Xmas period I had to top it up once per day. There aren’t that many reasons for this in a central heating system, so I availed myself of the Sealed Central Heating System FAQ. Read it. Now!
Sealed CH systems have to have a pressure release valve somewhere. Usually this is actually in the boiler, there certainly is one in the WB240. The pipe from this goes straight through my wall and down to the drain, so I put a bowl over the drain to catch any water, turned the heating on and went to do other things for 1/4 of an hour or so. When I came back the pressure in the system was just under 2 bar, but there was nearly 3/8 of a pint of water in the bowl! No wonder I was having to top it up a lot!
There are two reasons this can happen.
The pressure release valve is leaking.
The system is genuinely over-pressure.
The latter can happen if the expansion vessel is malfunctioning. The Sealed Central Heating System FAQ which you read earlier explains this. To test whether it’s the expansion vessel or not, you will need to find it. This isn’t difficult. It’s a large red thing. Follow the instructions below about Opening the boiler up.
In my case, the pressure in the system was nowhere near 3 bar and there was plenty of charge in the expansion vessel. Ergo leaking PRV. Flushing it through wasn’t working, so it had to be replaced.
Getting a replacement PRV
There’s nowhere local I know that’s likely to stock WB spares, so I got a replacement valve from Keep The Heat On. They’re not the cheapest on the web, but their delivery is good and they’re not too far away, so a visit isn’t out of the question. The valve in question is order code 108151. WB Part 8-716-142-416-0. It arrived the next day despite me picking the 2-3 day delivery.
Opening the boiler up.
Firstly, make sure that the boiler isn’t on and hasn’t been for some time. Then isolate it electrically. Somewhere you should have some means of actually turning the boiler’s electricity supply off. This may be near the boiler or near your main electrical distribution board. It could even have its own RCD (switch) in your mains electrical distribution board. When the boiler is powered down, there should be no lights on.
The rightmost pipe going into the boiler needs to be isolated, just as a precaution. This is the gas pipe. Turn the screw so that the slot faces across the pipe.
Now take the white front panel off the boiler. If you can’t figure out how to do this yourself, then you’re in trouble. Call a Registered Gas Installer!
At the top of the grey control panel are two screws. Not the ones facing you, the ones holding the grey control panel to the flanges at the side of the boiler. Supporting the grey control panel from the bottom, undo these screws. The whole control panel unit will then pull forward and hinge down. Note that the actions of pulling it forward and dropping it down are somewhat simultaneous.
The large red thing is the expansion vessel.
Testing the expansion vessel.
The valve for the gas charge is located on the right-hand side of the expansion vessel just above the white thing with the 4 pipes going in on the left and the drain tap on the right (I must try to work out what this is). The Sealed Central Heating System FAQ details how to test it. Mine had plenty of pressure in it.
Finding and testing the PRV
The 5th pipe from the left (2nd from the right) connects directly to the PRV. It’s right up the back of the boiler. How convenient.
The tap is on the right-hand side and is red. With the control panel dropped, I managed to get my left hand in under the “white thing” and over the top of the PRV so that I could operate the valve.
Highlighted in the image below is the pipe that enters the bottom of the PRV.
Now, if you’ve not tested a PRV before, this might take you by surprise :- they don’t turn back, only forward. Turn the top towards you; you will hear water escaping. Keep turning it the same way! Eventually it will snap back to the closed position.
If your leak doesn’t magically go away then you’re likely to need a new PRV.
Replacing the PRV: Isolating the CH and draining the boiler
I’m assuming here you have opened the boiler and dropped down the control panel (instructions for this are above).
OK, now we need to isolate the central heating circuit. Hopefully some clever spark has installed a pair of isolators other than the boiler’s own ones. If there is another pair, use them. If not, the two leftmost pipes on the boiler will have isolators on them at the bottom of the boiler. Turn them so that the screw slots face across the pipes, not along them. They may leak a bit, so beware.
If you haven’t isolated the gas, then do this now (instructions above).
You now have an isolated boiler, but it’s still full of water. Unless you plan on getting very wet whilst you’re working, draining the boiler is a good idea. To do this, just tweak the PRV so that water is flowing down the release pipe and leave it until it sounds like it’s empty.
Replacing the PRV: Spannering
Worcester Bosch have been quite cunning here. If you look just to the left of where the water pipe enters the PRV, there is a slot cut in the panel. This exposes the nut that connects the PRV to the pipe that extends leftward.
With the control panel pulled forward but pushed up, there is just enough room to get a spanner in here and work it to loosen the nut on the PRV. Don’t do that quite yet, though! First, undo the nut that connects the PRV to the waste pipe.
OK, now undo the nut on the left of the PRV. If you’ve ever worked on a Citroen, this will be small beer to you. If not, just persevere. There’s very little room to work the spanner and you have to be very patient!
So the PRV is free! Almost. Don’t go yanking it around. It’s still connected via a thick piece of copper wire to the pressure gauge at the front of the control panel.
Carefully ease the PRV downwards until you can get a spanner on the connector at the top. Undo this, then the PRV is really free! If you’re feeling brave, you can test it once and for all :- I turned it to make sure it was shut, covered the pressure gauge socket with my thumb and then blew through it. The problem being that I did in fact blow through it. These gauges are supposed to open at 3 bar and there is no way I can provide 3 bar of pressure with my lungs!
Now, in the style of a Haynes manual, reassembly is the reverse of disassembly, only with the new PRV, of course. I added a bit of PTFE tape to the threads. It’s probably not required and may make matters worse, although I can’t think why.
Recommissioning the boiler
DO NOT THINK YOU CAN JUST TURN THE BOILER BACK ON! The boiler will still be full of air!
It is worth mentioning here that I don’t have the official Worcester Bosch instructions for recommissioning, and I don’t know what they are. This is what I did and it worked.
Ensure that the CH circuit is no longer isolated. You will hear the boiler gurgle a bit as (some) water flows back in.
Ensure that the gas still is isolated.
Turn the electricity back on. Then cause demand from the CH system (select Heating and Hot water and then tweak the controller until the boiler attempts to fire up). Clearly the burner will not work, but everything else will. It will attempt to pump water round the system. If the pump makes a horrible noise, check its temperature. If it becomes uncomfortable to touch, turn it off and wait until it has cooled down, then give it another few minutes. Eventually the boiler should sound pretty much like it did before, but without the burner running, obviously.
Now turn it back off, turn the gas back on and fire it up!
If there’s still air in the heat exchanger, it may well trip the overheat protector. This is the strange little button on the top of the control panel. It should be pressed in. If it pops out, the boiler will stop. If this happens, turn off the gas and run it for a few more minutes without the gas on, then give it another go (you will need to press the reset switch in again).
Apparently there are other, better ways of getting the air out of the boiler. There is a bleed nipple on the pump; there may be one on the heat exchanger, too. Unfortunately, I don’t know anything about this! If you do (or manage to find out) then please let me know!
A little note: this article was written in 2010 – the principles of a semaphore haven’t changed in decades, but the code included is somewhat out of date now.
No, you’ll be glad to hear that Semaphores in computing don’t involve standing in a prominent position and waving your arms around like a lunatic. Semaphores are handy little constructs that are especially of use in producer / consumer scenarios; indeed, this is by far the easiest way of explaining them. I find imagining the semaphore to be a person, a supervisor, to be the best way of visualising it. Every time one of the producers has some work, it hands it to the supervisor. If there are no workers (consumers) waiting for work, the supervisor stores it until such time as one asks for more. The important thing about a semaphore is that if there are no work items, the supervisor makes the workers wait.
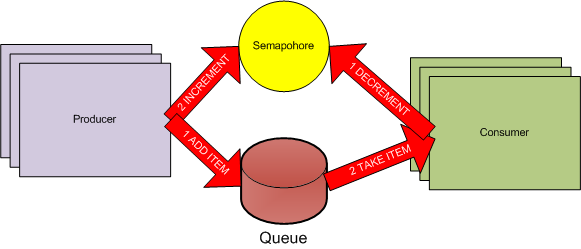
So, to the semaphore itself – they act most like accumulators: you increment and decrement them. Worker threads (consumers) try to decrement the semaphore. If the semaphore is already at zero and a thread tries to decrement it, that thread will wait. Producers increment the semaphore. It’s important to note that if multiple threads are waiting on a semaphore and the semaphore is then incremented by one, only one thread will be released. The rest will remain waiting. There’s a more real-world example in the diagram beneath…
Semaphore and Queue
In said diagram, there are several producers. When a producer has an item, it always follows a strict sequence: it adds the item to the queue and then increments the semaphore. The consumer threads do the reverse: they know that if they can decrement the semaphore, they can safely take an item from the queue. Of course, if the semaphore drops to zero, then consumer threads will have to wait until a producer increments the semaphore. At this time, one consumer thread will be released to process the added work item. There’s an example of this in action in this zip file (C#, VS2008), extract beneath.
static void Consumer()
{
string item;
int queueLength;
do
{
mySemaphore.WaitOne(); // wait for an item to be available
lock (myQueue) // queue isn't thread safe so we need to lock.
{
item = myQueue.Dequeue();
queueLength = myQueue.Count;
}
if (!String.IsNullOrEmpty(item))
Console.WriteLine(String.Format("C{0:00} DEQUEUE Q{1:00}: {2}",
Thread.CurrentThread.ManagedThreadId, queueLength, item));
Thread.Sleep(250);
} while (!String.IsNullOrEmpty(item)); //we use null to signify end of processing
}
static void Producer()
{
int queueLength;
foreach (string line in Shelley)
{
Thread.Sleep(random.Next(1000));
lock(myQueue) //queue isn't thread safe so we need to lock.
{
myQueue.Enqueue(line);
queueLength = myQueue.Count;
}
mySemaphore.Release(); //let any waiting consumers go.
Console.WriteLine(String.Format("p{0:00} enqueue Q{1:00}: {2} ",
Thread.CurrentThread.ManagedThreadId, queueLength, line));
}
}
Without semaphores, ensuring that the producer / consumer model works efficiently tends to become either very complex or inefficient.
That’s really all there is to say about semaphores, apart from the fact that you shouldn’t limit your thinking about them to producer / consumer scenarios; they can actually come in surprisingly handy elsewhere.
Message Passing
Message passing is massively important in most of today’s GUI applications, yet it’s surprising the number of people who have no real idea what it’s about. In order to understand message passing, though, you really need a basic understanding of what a thread actually is. It’s a procedure. Regardless of wrappers etc., when you create a thread what you actually say to the scheduler is “take this block of code and execute it in parallel with everything else I’m doing”. If you look at the code above, you’ll notice two static methods; Producer and Consumer. These form the code block for threads – 2 copies of Producer and 3 of Consumer are run at the same time. If they were a straight block of code, execution would fall off the end and the thread would end. Both, however, loop until some condition is met, when they stop.
It’s important, if you do use loops in threads, that there is some end condition so that they can stop when the program ends.
The main thread in the majority of GUI applications is exactly like this :- it actually runs a simple loop that waits for messages. When it gets a message, it performs some sort of action (usually calling a handler) and then returns to waiting for the next message. In this context, a message is likely to be a mouse click, a key press or an instruction to minimise and these come from the operating system, but it could equally well be an instruction that we generate ourselves.
Why do we do it? Well, in the case of most GUI apps it ensures that everything that happens to the GUI happens in one thread. If the handlers are well-written, then every action starts with the GUI in a stable position and finishes leaving the GUI in a stable position.
We can look at it as a transaction processing system: transactions (messages) are serialised on the queue and each one is executed discretely.
All we need to do this ourselves is a thread that loops on some sort of queue, waiting for a message to arrive and some sort of message structure for it to process. This is an extremely powerful technique, but it isn’t without its hazards. As much as it can be used to aide thread safety by ensuring that access to data and resources is correctly sequenced, it can just as easily ruin thread safety, particularly as the exact time when a message is going to be processed cannot be known, therefore the lifetime and access to any data shared between threads must be very carefully considered.
Windows itself provides a standard framework for message passing that contains two fundamental ways of passing a message – PostMessage and SendMessage. No, the names are not brilliant. PostMessage puts a message on the queue for the message processing thread and continues running. SendMessage by comparison puts a message on the queue for the message processing thread and then blocks the calling thread until the message has been processed.
In WPF we can look at the Dispatcher framework – that’s an easier to use version of the same thing.
If, before I mentioned that last bit, you hadn’t realised that Message Passing opens up a whole new world of pain when it comes to deadlocking, you should now. Imagine what happens if a handler in thread A does a SendMessage to thread B, which then tries to lock a resource that thread A has locked.
If you’re programming with message passing it’s more important than ever to ensure what state your data is in at any moment and what has access to it, but you must also keep on top of flow and make sure that deadlock situations can’t arise.
OK, I suspect I’m a little bit of a nerd about this, but I actually find it quite fun to look at designs and work out where the deadlocks can happen, but it’s from years of playing about with this that I understand exactly what is likely to happen and why.
Next time I’ll start looking at how the constructs provided in C# and the .NET Framework 3.5 help us with threading.
Here’s a really crafty use of the .Aggregate function of C#’s LINQ.
x = IQueryableOfSomething.Select(n => n.ToString()).Aggregate((p, q) => p + ", " + q));
It produces a comma separated list of the items in IQueryableOfSomething. So if it were a list of colours one might get:
Red, Green, Orange, Blue
The cunning thing about it is that there are only separators between the items, there isn’t an extra one at the end. Coping with this in inline code always makes it look pants. This is much cooler.
[ EDITS ]
Having initially posted this an “anonymous coward” pointed out that in the initial case one can use String.Join. This is true but my point really wasn’t specific to this instance. The idea was to start thinking outside the bounds of the normal boring aggregate operations. It’s a much more useful feature than just sums and averages. e.g.
What does this do? It creates a one byte checksum for an IEnumerable<byte>. Checksums are really useful if the storage or transport you’re using is not 100% reliable – you send / store the data with its checksum.
When you read it back you calculate the checksum again. If it doesn’t match the one stored / sent with the data then there’s been a corruption (either in the data or the checksum).
Of course this only uses a byte so there’s a 1:255 chance that the data is corrupt but the checksum is correct nonetheless. There are many ways of creating checksums less prone being randomly correct despite the data being corrupt. One has to weigh up the severity of this eventuality against the computational and space / transport cost of more resilient options.
Reading Time: < 1minuteHull University's Rob Miles on the Tech Ed Banner
Useless trivia and because there’s no way that Rob is going to put this on his own blog….
If, before it had taken place, you visited Microsoft’s Tech Ed North America’s site for 2010 you’d have seen the above banner (in full). The person I’ve highlighted is my colleague at The University of Hull, Rob Miles.
Reading Time: 4minutesSo last time I left you with the horror of deadlocks. To recap, a deadlock is when two (or more) threads can’t continue because there’s no way that they can get the resources that they need. A simple deadlock can occur when two threads, let’s call them A and B, both require access to two locks, but lock them in different orders.
Thread A locks resource 1
Thread B locks resource 2
Thread A tries to get a lock on resource 2 but can’t until Thread B unlocks it
Thread B tries to get a lock on resource 1 but can’t until Thread A unlocks it.
Stage 4 of the above can never succeed because Thread A is waiting for Thread B already. They’re mutually locked out, or deadlocked.
One of the easiest things to say about avoiding deadlocks is that you should always lock the resources in the same order. This will indeed prevent deadlocks and it works really well in simple little examples, but when you’re elbows deep in a myriad of objects and there’s all sorts of stuff flying around it can be difficult to ensure that this actually happens. That doesn’t mean abandon the idea, indeed I would suggest attempting to make sure that it’s the case anyway, but it’s not always practical to ensure.
Let’s look at the savings and current account example again. This is how it was…
BankAccount currentAccount;
BankAccount savingsaccount;
void moveFromSavingsToCurrent(int amount)
{
//we need to work with savings, so lock it
lock(savingsAccount)
{
if(savingsAccount.Total>amount)
{
//we can proceed, but we don't want any inconsistencies so we now need
//to lock currentAccount
lock(currentAccount)
{
savingsAccount -= amount;
currentAccount += amount;
}
}
}
}
void moveFromCurrentToSavings(int amount)
{
//we need to work with current, so lock it
lock(currentAccount)
{
if(currentAccount.Total>amount)
{
//we can proceed, but we don't want any inconsistencies so we now need
//to lock savingsAccount
lock(savingsAccount)
{
currentAccount -= amount;
savingsAccount += amount;
}
}
}
}
We can actually fix this one really easily.
BankAccount currentAccount;
BankAccount savingsaccount;
void moveFromSavingsToCurrent(int amount)
{
//we need to work with savings, so lock it
lock(savingsAccount)
{
lock(currentAccount)
{
if(savingsAccount.Total>amount)
{
savingsAccount -= amount;
currentAccount += amount;
}
}
}
}
void moveFromCurrentToSavings(int amount)
{
//we need to work with current, so lock it
lock(savingsAccount)
{
lock(currentAccount)
{
if(currentAccount.Total>amount)
{
currentAccount -= amount;
savingsAccount += amount;
}
}
}
}
By taking the two locks out every time and always in the same order we prevent the deadlock, but now we’re always having to perform both locks, which will be a performance hit. Is there a better way?
Possibly, if we always need to lock both for every operation that we do then we could simply use one lock instead. In fact, simplifying the locking strategy is a great way to reduce the possibility of deadlocks and done well can actually improve performance. After all, the more locks there are, the more chance of a deadlock.
Another trick is to test locks, either with or without a timeout. In order to do this we need to move away from the simple lockstatement and explicitly use a mutex or similar). In doing so we break out of the simple c# constructs into the world where we must know what we or doing, or it will hurt us.
Mutex m = new Mutex();
...
m.WaitOne();
try
{
access the required resources...
}
finally
{
m.ReleaseMutex();
}
Here’s the simple construct to using a Mutex. It’s an object in c# so we need to create it. We then call WaitOne() on it when we need to get the lock and we call ReleaseMutex() when we’re done. It’s always good to try to do this in a try…finally because the number of times a Mutexis acquired (with WaitOne()) must match the number of times it’s released (ReleaseMutex()). This may sound silly, but a thread can actually acquire a Mutex more than once, for instance in a recursive function. If an instance of that function threw an exception, it could leave the Mutex with more acquisitions than releases, which would be a problem and would cause an exception to be thrown when another thread attempted to acquire it. A thread must exit leaving all Mutex releases and acquisitions balanced.
Apart from that, it’s just like a lock. Our personal finance example again…
So what about this waiting for a timeout business? Well there are several overloads of WaitOne() which basically allow you to specify some sort of timeout. WaitOne() then returns a boolean, if the wait is succesful and the Mutex is acquired, WaitOne() will return true. If it fails and times out, WaitOne() will return false. Note that although you can use this to get you out of a deadlock, it’s a bit of a hack. Programming it properly in the first place is a better idea. In fact, the amount of error handling code that’s required to avoid nasty consequences may well be greater than the amount of code required to make it work properly in the first place.
I mentioned in my last also also that there is the phenomenon of the compound deadlock. This is the one that really gets programmers frustrated because a simple deadlock like the one in our savings account example is relatively easy to spot. In reality deadlocks can be long chains of events, the chances of which happening can be millions to one. Code that has run fine for years can suddenly start deadlocking one one machine. Why? Something very subtle with the timing has changed. Maybe an operating system change, maybe a new piece of hardware that just happens to cause the particular sequence of events in the particular order at the particular times. The worst thing is that there’s no stack trace, no debug. Often it can’t even be made to do it in the debug environment, the only place it will do it is at the customer site.
Nest time I’ll talk about semaphores and I may even get on to semaphores.
By the way, I’m intending to tidy these articles up, provide more examples and link them together a bit later.
Reading Time: 4minutesSo in this article on thread safety I finally get to talk about locking. Why has it taken me until article 3 to talk about this? Well, it’s not quite as straightforward as it first appears. Firstly there’s more than one type of lock. Secondly, there are hazards and pitfalls. Picking the wrong locking strategy, or implementing it badly can cripple performance rather than improving it. Then there’s the deadlock, it’s positively evil twin the compound deadlock and I’ll not even mention deadlocks that also involve message passing.
But before I start complicating matters with tales of horror, let’s take it right back to basics. In the examples from article 1 (C#, VS2008), in the not thread safe project there’s a comment to the effect that, to make the program thread safe, all one has to do is uncomment a lock statement.
public static void DoAddition(object obj)
{
int tempVal;
Thread.Sleep(rand.Next(10));
/*
* All you have to do to make this thread safe is uncomment this lock statement
* Try it!
*/
//lock (threads)
{
tempVal = accumulator;
//wastes some time simulating a complex calculation
for (double f = double.MaxValue; f > double.Epsilon; f *= 0.5f) ;
accumulator = tempVal + 1;
}
}
The C# lock statement is a great example of a simple mutual exclusion lock. What we’re saying with the lock statement is to take a named variable, in this case threads and apply a mutual exclusion lock to it. This lock is in place whilst the code in the block (between the curly braces) is running and ends when we leave that block. What is the effect of this? Well, it means that if another thread tries to place a lock on the same variable (e.g. threads) whilst we’re executing the code block, it will have to wait until the our code block has finished.
If we revisit our example from the first article where we managed to accidentally declare our love to Dave, but this time use a lock, we can see the effect. The first thread locks msg, the second thread attempts to jump in and use msg whilst the first is still working with it. But when it tries to “acquire the lock” it can’t and has to wait until the first thread has finished and “releases the lock”. It’s worth noting that if a third thread jumped in, it would also have to wait.
The lock statement saves the day
Remember though that there’s no psychic element to the lock statement, or mutexes in most languages. Let’s look at a producer / consume example.
Queue<WorkItem> workQueue=new Queue<WorkItem>();
...
void processQueue()
{
bool weNeedToProcess = true;
do
{
WorkItem itemToProcess;
lock(workQueue)
{
weNeedToProcess = workQueue.Any();
if(weNeedToProcess)
itemToProcess = workQueue.Dequeue();
else
itemToProcess = null;
}
if(null != itemToProcess)
{
do some things...
}
}while(weNeedToProcess);
}
...
void someMethod()
{
//we need to queue a workItem
WorkItem newWorkItem = new WorkItem(someTask);
workQueue.Add(newWorkItem);
}
The processQueue method runs in a background thread processing items of work which are put on the queue by other threads. The problem though, is that in someMethod was have forgotten to lock workQueue which means that it’s not thread safe. When we add an item to the queue, processQueue could be in the middle of taking an item off the queue and all sorts of things could go wrong.
Fixing this is easy…
void someMethod()
{
//we need to queue a workItem
WorkItem newWorkItem = new WorkItem(someTask);
lock(workQueue)
{
workQueue.Add(newWorkItem);
}
}
So that’s one danger. Now let me introduce on the Great Satan of all multithreading, the deadlock. It’s really quite easy to explain a simple deadlock, thread a needs a lock that thread b has got at the same time as thread b needs a lock that thread a has got. Let’s go back to our savings account and current (or checking) account scenario.
BankAccount currentAccount;
BankAccount savingsaccount;
void moveFromSavingsToCurrent(int amount)
{
//we need to work with savings, so lock it
lock(savingsAccount)
{
if(savingsAccount.Total>amount)
{
//we can proceed, but we don't want any inconsistencies so we now need
//to lock currentAccount
lock(currentAccount)
{
savingsAccount -= amount;
currentAccount += amount;
}
}
}
}
void moveFromCurrentToSavings(int amount)
{
//we need to work with current, so lock it
lock(currentAccount)
{
if(currentAccount.Total>amount)
{
//we can proceed, but we don't want any inconsistencies so we now need
//to lock savingsAccount
lock(savingsAccount)
{
currentAccount -= amount;
savingsAccount += amount;
}
}
}
}
This will cause any experienced multithreaded programmer to scream in horror. Why?
Let’s say an instance of moveFromSavingsToCurrent and moveFromCurrentToSavings are run simultaneously and they interleave like this…
moveFromSavingsToCurrent acquires the lock on savingsAccount
Meanwhile, moveFromCurrentToSavings acquires the lock on currentAccount
moveFromSavingsToCurrent asks for the lock on currentAccount, but has to wait until the thread running moveFromCurrentToSavings has finished with it.
moveFromCurrentToSavings asks for the lock on savingsAccount, but has to wait until the thread running moveFromSavingsToCurrent has finished with it.
moveFromSavingsToCurrent can’t continue until moveFromCurrentToSavings releases the lock on currentAccount. The problem is that moveFromCurrentToSavings can’t progress and therefore can’t release its lock on currentAccount because it’s waiting for access to savingsAccount, which moveFromSavingsToCurrent has. These two threads will sit there doing nothing until they’re killed. That will probably be the end of your application, when the user finally gets irritated enough to forcibly close it.
Let’s have a go at diagramming that…
A Simple Deadlock
I’m not sure that makes it any clearer but often seeing information presented in different ways suddenly makes it click.
Next time I’ll talk about avoiding simple deadlocks and introducing the real big hitter in the stakes of debugging hell, the compound deadlock.
Reading Time: 4minutesSo I left you hanging last time. I teasingly introduced three things you can do to combat thread safety problems and then didn’t adequately explain any of them. Let’s start putting that right. First I’m going to explain more about why local variables are (usually) thread safe.
The really important thing to get your head round is the difference between value types and reference types. If a variable is an instance of a value type this means that when the CPU wants to work with it, it can access the value directly. Say we have an int, that’s a value type. When the CPU wants to work with an int it can just look at it and see the value.
If it is a reference type though, the CPU can’t access the value directly, instead what it can see is a reference to where the value is held. It can then go and get the value.
Objects are always reference types.
To demonstrate, if we have a class…
class snaf
{
public void kung()
{
int foo = 10;
ComplexObject bar;
do some things...
bar = new ComplexObject();
cookTheBooks(foo, bar);
do some other things...
return;
}
}
When we call the method kung, the variable foo and an empty reference to bar are created locally. int is a value type, whereas ComplexObject is a reference type.
Moving on a stage, we create an instance of ComplexObject and put a reference to in in bar. The actual memory used to store the new CompexObject is not local, but on the heap (which is just a big pile of memory that we have access to). After this we call another method and pass these two variables (foo and bar) in. Now we will be able to see the importance of the difference between reference types and value types, and passing by reference and passing by value.
What will happen when we return from this method back to kung? When we passed in foo it was 10. You might be surprised to know that the value of foo will still be 10, but the value of bar. Total will be 11 times what it previously was.
How? Well foo is a value type, so it was passed by value. This means that the instance of foo in cookTheBooks was actually a copy of the original foo. This means that when cookTheBooks incremented foo, it only incremented a copy of foo, not the original. When cookTheBooks returned its copy of foo was discarded and we were left in the method kung with the original foo, value still in tact.
In contrast, bar is a reference type. When we passed this to cookTheBooks what we actually passed was a copy of the reference. Spot the problem? A copy of the reference points to precisely the same location in memory as the original. So when we modify bar.Total we are modifying the original. Hopefully this diagram will make it a little clearer.
Values vs. References
We can actually choose to pass a value type by reference (in C# by using the ref keyword). When we do this the method is not passed a copy, instead it is passed a reference to the original and any changed made in the method will change the original.
If we’d done this when we passed foo to cookTheBooks, when we incremented foo we would have incremented the original.
But we don’t want to do that here! We’ll stick to the original pass by value version. So how does this rather long and complicated explanation affect thread safety? Well, every time kung is run, a new foo and a new reference to bar are created. Unless we explicitly pass foo by reference to something else, it’s inherently thread-safe. Nothing else can get to it. To re-iterate – every instance of a value type that we create in a method is thread safe unless we explicitly pass it be reference somewhere else. Member variables, even if they’re private value types, are not thread safe. If your object is used in multiple threads you have to deal with thread safety yourself.
As a reference type, bar‘s thread safetyis not so straightforward. If it’s a simple object and we don’t pass it to anything, then as we have the only reference to it it must be thread safe. However, if bar is not a simple object, maybe a singleton, or maybe something that uses certain types of system resources, it might not be thread safe itself. So we have to be very careful about the assumptions we make with bar.
What impact does this have on the way we program? Well, it’s about scope. Consider this implementation…
class snaf
{
private int foo = 10;
public void kung()
{
ComplexObject bar;
do some things...
bar = new ComplexObject();
cookTheBooks(bar);
do some other things...
return;
}
private void cookTheBooks(ComplexObject bar)
{
foo++;
bar.Total=bar.Total*cookFactor;
return;
}
}
Here foo is a member variable. It’s created when the class is created, not when each instance of kung is called. If two threads happen to call kung at the same time, both will try to access the same instance of foo. This could have disastrous results.
This is just one of the reasons why managing scope is important.
Looking back at something you wrote years ago is weird. The style is familiar but the content is not – quite often to the extent of wondering what mind altering substances might have been affecting your consciousness when you came up with that.
Laziness is your enemy – don’t make the mistake of thinking that your code is going to become someone else’s problem at the end of the project, or when your secondment / contract is over, etc. Old code has a habit of coming back to haunt you… just because the project has an expected life of 2 years doesn’t mean that in 4 years time you won’t suddenly find yourself staring at the botch job you’re making right now and wondering whether there was something psychoactive in the Smarties.
What’s more, you’ll be staring at it because it’s started going horribly wrong, customers are queueing up to litigate and nobody can work the damn thing out. The entire product team right from the salespeople to the board of directors will be calling you every half hour for progress reports, so it sort of helps if you can work out what you were trying to achieve when you wrote it.
Always make sure your code is maintainable. Comments are your friends.
Anyway, that wasn’t the point. I was talking about how odd it is looking at old code. My coding style is a quite unusual – I’m quite declarative and functional. I can pick out code that I’ve written pretty easily. Every now and again though I come across someone else with a similar style. It’s really, really odd looking at code and not knowing whether you wrote it and have forgotten it, or whether it was someone else.
Let’s talk about multi-threading and concurrency. Why? Because we need to. Developers have been trying their best to avoid it for years because a lot of people have a really hard time with it. The problem is that it’s about to become really important. The chip manufacturers have hit a hard limit on the speed of processors, the can’t make them go any faster. What they can do is add more cores: 2 core and 4 core are common at the moment, but 8 is on its way to the desktop soon and this number is just going to go up and up.
The upshot is that if you’re still programming in a sequential, single threaded model your products going to be killed in the marketplace by competitors who actually know what they’re doing.
Why am I being so vocal about this? Well concurrency is not something you can busk, if you don’t fully understand the problems you’ll land yourself in a world of pain. I know, I’ve spent weeks tracking down multi-threading bugs introduced by developers who thought they knew what they were doing (including me). It’s a hell of a lot better if you don’t introduce the problems in the first place.
First let’s first clear up a few simple misunderstandings. A thread is a sequence of actions that can run in parallel to another sequence of actions. A thread is usually made from a method or function call. It doesn’t have any relationship with objects other than the fact that some environments provide handy thread management objects. A thread can use one object, multiple objects or none at all. An object can be accessed by many threads. There’s no magic thread safety between objects, contrary to what some people seem to think. Unless you’ve implemented some thread safety measures acting on one object from another is not “thread safe”.
In C# you can use threads directly, but more often you would use the Task Library or the Parallel library. Microsoft are clear that both these libraries use threads, so if you’re using these libraries you need to understand threading and concurrency. They’re no get out of jail free card in that respect.
So here’s a trivial example of why threads are useful. A simple GUI application has only one thread. The user clicks something and whilst the action behind that is being performed the user has to wait, the GUI won’t even be updated so if it’s a long task the application will be unresponsive until the action completes. Instead we could start a second thread to perform the action in parallel to operating the GUI. The application now won’t freeze whilst we’re performing the action, and when it completes we can tell the user.
Here’s a simple diagram of that and you can download an example in this zip file (c# / VS2008).
Why Single Threaded GUIs are So Limited
So where’s the danger? Well, the basic problem is mind-numbingly dull. The next diagram shows an example that I see annoyingly often with object initialisation.
Poor programming causes many problems...
Time runs from top to bottom with two threads are running simultaneously. Both of them are trying to deal with one email object, but the timing between the threads screws things up for us and we end up declaring our undying love for Dave, twice. To add insult to injury, we also end up creating a spurious email object. Whilst in a managed language the garbage collector will pick this up for us (which is bad, but not criminal), in an unmanaged environment we’ve just introduced a memory leak and that’s a defenestration offence. This is not a good day at the office.
As an aside, don’t be fooled into thinking that this can’t happen if you’re only running on one core. The way threads are (usually) scheduled on a single core means that this kind of thing is entirely possible.
The key is that anywhere where changes are made to something that is accessed by more than one thread there can be a problem, it’s not just where multiple threads are making changes either. Consider a personal finance object. One thread asks it to move £20 from the current account to savings. It duly takes the money off the current account but before it adds it to the savings account another thread reads the balance of the current account and savings account and adds them together to get the total available funds, which at that precise moment is wrong. The personal finance object then adds the £20 to the savings account and you have no idea where the incorrect total came from or even that you have one. The examples zip file (c# / VS2008) contains a ludicrously simple program to demonstrate the problem.
One fallacy that I’ve heard from even quite senior and experienced developers is “ah, but what are the chances of that actually happening?” In the personal finance case, on a single core, actually it’s not a lot and this is why people have got away with writing appalling multi-threaded code for so long. But with a more complex operation or one on multi-core processors the chances of this kind of assumption screwing you over are significant.
So what weapons do we have in our arsenal to fight this kind of cock-up? There are three fundamentals, managing scope, managing locking and message passing. Scope is the easiest to cover so I’ll do so now, locking and message passing will have to wait for until the next article.
So, scope: remember way back in programming 101 that you were told to manage scope? A lot of threading problems happen because things are shared between threads when they shouldn’t be and it really is that simple. Local variables are your friends because they are created when the method is called and go out of (at the very least) scope at the end of the method. If two instances of the method are called on the same object at exactly the same time, there will be two totally separate instances of the local variables. If something isn’t shared with any other thread, it is by definition thread safe. Use local variables instead of private member variables where it’s practical to do so.
There are caveats, such as singletons and other objects that share resources, but any basic variable or object is thread safe if it’s only a local variable. For pedants, I must now mention the speed implications and that passing them by reference somewhere can make them unsafe, I’ll cover more of those in the next article.
The next most safe is private member variables. Our object has control over the way these are accessed so we can ensure that they’re used in a thread safe manner. A list can make sure in its add, delete and access methods that it carries out the correct locking on its internals so as to make sure that nothing that is not thread-safe happens.
There’s not a lot we can do about publicly accessible entities though. At least if they’re properties we can control the way they’re got and set, but we can’t guarantee our own consistency. The email example shows this, where the email’s properties are being set externally and it’s the external logic, not the logic in the object that isn’t thread safe. We can combat this by introducing internal controls on the way properties can be set, for instance we could have made To and Subj read only and introduced a SetHeaders method that took both at once and was thread safe, but overuse of this technique can make code less clear and hamper productivity. It’s also somewhat treating the symptom, rather than the cause. There’s no substitute for getting it right in the first place.
Next time I’ll explain more about exactly why local variables are (generally) thread safe and look at message passing. Don’t worry, I’ll start looking at locking in post 3.


![[picture of screw]](https://www.tomfosdick.com/wp-content/uploads/2026/06/screw.jpg)