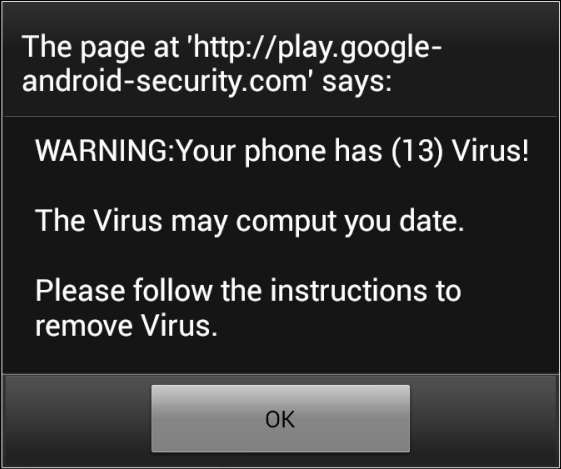
It appears that Tweetcaster has just become Spamcaster – it threw a message up on my phone telling me that I had 13 Virus[sic]. I deleted the application immediately and as a precaution checked that it was the only application from “One Louder Apps” that I had.
I’m very disappointed with “One Louder Apps”. I appreciate that all software houses have to make money (hell, we do) and I’m fine with that. I’m fine with free apps being supported by advertising. What I’m not fine with is allowing an application to be hijacked by a con. My phone does not have any viruses and the site / software I was being linked to would almost certainly install malware rather than removing it.
Anyway enough ranting. This got me thinking though about some of the less desirable near inevitabilities of app development.
In the software industry we love the app stores because the barriers to entry to this market are small. You don’t need to be a huge software house with massive resources to write some really clever and useful apps.
There’s a flip side to this coin though, if the barriers to entry for you are low then the barriers to entry for your competitors are also low. Consider the following (rather simplified) story.
You and a mate have a really cool idea for an app. You start coding it in your spare time and release an early version to the market place. It starts getting noticed. At the same time it’s noticed by customers it’s also noticed by potential competitors. They start designing similar apps, ones that have all the features yours does and a few more on top, but it’ll be a while before they get to market. So you have a golden window to make your app the best you can and get the cash in before there’s any real competition.
You’re making a bit of money out of it now though which means you can hire a couple of extra coders. So you all start hacking in features as fast as you can and the app rises in the charts, the revenue rises and everything is looking good. You buy a Porsche.
The code is suffering however from all the hacking and soon you notice that you’re having to do a lot of rework to add a feature. What’s more when you add a new person to the team your output doesn’t seem to increase by one person’s worth, more like half of a person. This is because you’re finding that you’re having to introduce procedures for things, and do documentation and all that overhead that you didn’t have to do when it was just 2 of you. But hey, the money’s flowing in, everything is rosy.
No actually, because if at this point you’re not well on the way to implementing the next killer feature then you’re screwed. Those apps that were designed after yours came to market are going to start coming online. What’s more because they designed in features that you had to hack in later they’re going to be more swish and because their code is still fresh they’re going to be able to implement new features with much less effort than you.
Even if you have got that next feature lined up you’re still in a race that you’re unlikely to win in the log run. You can’t recover your initial velocity, it’s just not possible with a hacked-to-bits code base. It’s always going to cost you more to develop anything than the newcomers to the market. With revenue falling as your market share decreases you can’t afford to throw enough people at the project to brute-force your way back to the top.
Unless you can find some way of drastically increasing your income stream it’s time to put your head between your legs and kiss your Porsche goodbye.
It’s not all doom and gloom though, there are a few ways you can combat this. Not every app / software house crashes and burns quite so pathetically.
For games especially you can release alternative versions – “in space”, “Star Wars edition” etc. that are basically the same code with a few visual tweaks. I could name several game franchises that have been able to do this very well indeed. You can even release “new” games that are substantially the same code as the old and hence don’t need that much development.
If you can use the ascent and some of the initial revenue of the first application to get a second one off the ground then as long as you keep having good ideas for apps you can keep a flow of applications. As one dies the next will become your major revenue earner.
If you use more formal development techniques from day 1 then you’re never really going to have that big burst of activity in the early phase but you’ll be able to build on what you’ve done and maintain your velocity. Competitors will come and go, your app will fluctuate in the marketplace but you stand a reasonable chance of keeping it near the top for a long period of time.
It’s quite fun to look at the successful apps and app developers in the market place and try to work out which they’re doing. Clearly the likes of Microsoft, Google, Facebook etc. are so big they’re largely irrelevant. They need to have the apps, they don’t necessarily need to make money directly from them and they can hurl seemingly unlimited resources at them if needs be.
Most of the smaller firms though you can see quite clearly what their business strategy is.